If you work with large datasets or build data pipelines, chances are you’ve come across the Parquet file format. Parquet is widely used in data lakes, analytics engines like Apache Spark, and cloud platforms like AWS Athena, Snowflake, and BigQuery.
But what exactly is Parquet? And how is it different from formats like JSON or a relational database like SQL?
Let’s explain it with real examples and clear comparisons.
Table of Contents
📦 What is Parquet?
Parquet is a columnar, binary file format optimized for efficient analytics queries on big data. It was designed to support:
- Fast reads (especially for selective columns)
- Efficient storage via compression and encoding
- Scalability through partitioning and row groups
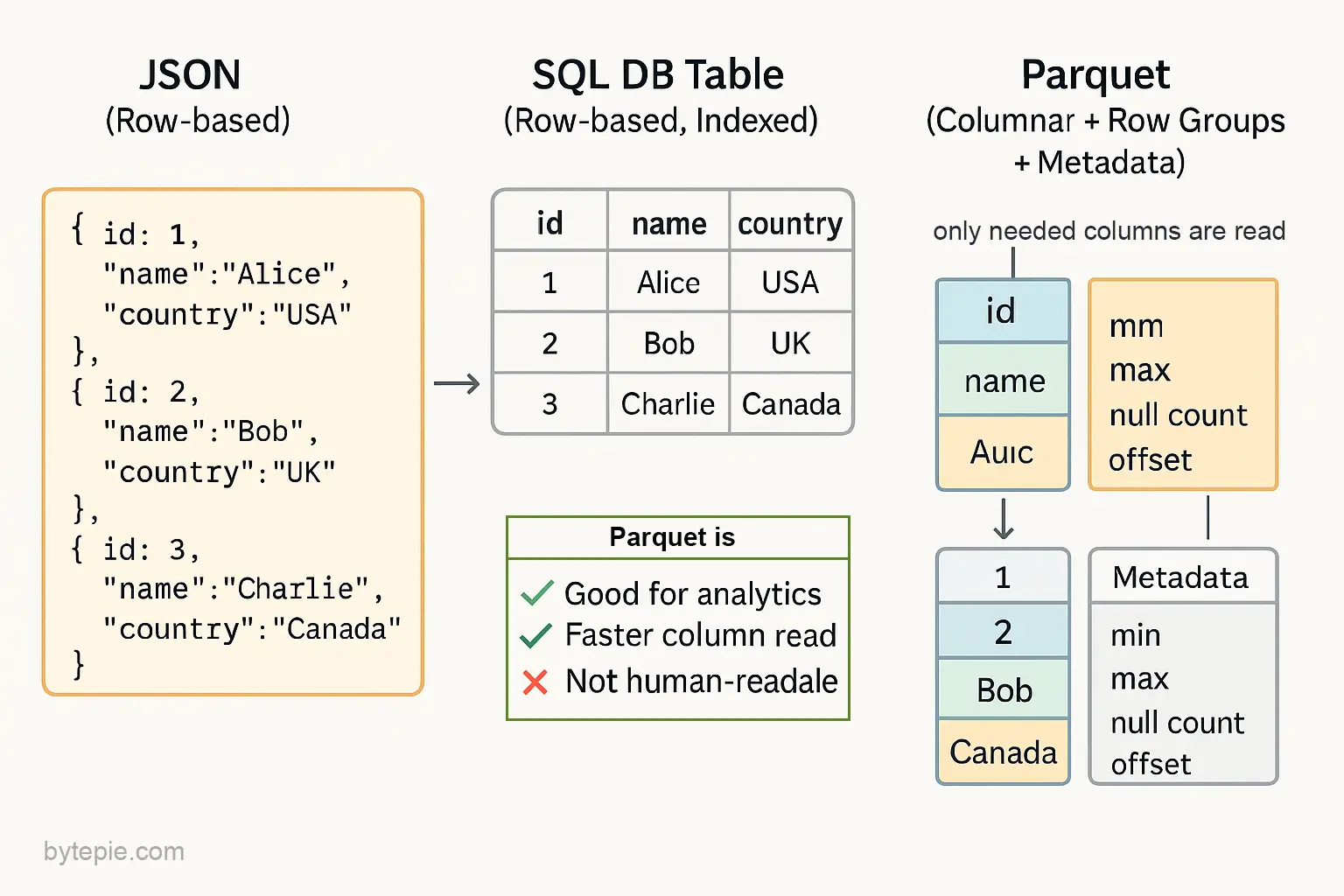
Instead of storing rows together like CSV or JSON, Parquet stores data by column, making it possible to load just what you need — perfect for analytics workloads.
🆚 JSON vs Parquet
| Feature | JSON | Parquet |
|---|---|---|
| Structure | Row-based (records) | Column-based |
| Read Speed | Slower (read full file) | Faster (read only needed columns/groups) |
| File Size | Larger | Smaller (compressed, encoded) |
| Readable Format | Human-readable | Binary (machine-friendly) |
| Nested Support | Yes | Yes (supports complex structures) |
| Use Case | Data exchange, config | Analytics, big data processing |
JSON Example:
[
{ "id": 1, "name": "Alice", "country": "USA" },
{ "id": 2, "name": "Bob", "country": "UK" }
]
Parquet (Conceptual Layout):
Column: id → [1, 2] Column: name → ["Alice", "Bob"] Column: country → ["USA", "UK"]
When querying for country, Parquet skips the rest — JSON can’t.
🗄️ Parquet vs SQL (Relational Databases)
| Feature | Parquet File | SQL Database (e.g. Postgres, MySQL) |
|---|---|---|
| Type | File (immutable, offline) | Live database with engine |
| Data Access | Read-only (append supported) | Read-write, transactional |
| Performance Focus | Analytics (OLAP) | Transactions (OLTP) |
| Query Engine | External (DuckDB, Spark, etc.) | Built-in SQL engine |
| Use Case | Large datasets, ML, dashboards | Web apps, real-time systems |
Parquet is a file format — not a database — but you can still query it using tools like DuckDB, Spark, Pandas, or Polars.
🔥 Why Is Parquet So Fast?
Parquet is designed for speed. Here’s how it works under the hood:
1. Columnar Storage
Parquet stores each column together — not each row. So if you only need name and age from a 100-column dataset, Parquet only reads those two columns.
2. Row Groups
Parquet breaks data into blocks called row groups, typically 128MB or 512MB each. Each group contains a subset of rows — but still stores columns separately inside.
This means Parquet can:
- Skip irrelevant row groups during queries
- Parallelize reading across groups
- Improve cache efficiency
3. Column Chunks + Pages
Within each row group:
- Each column is stored as a chunk
- Chunks are further split into pages
- Pages are compressed and encoded (e.g. dictionary, RLE)
4. Metadata and Statistics
Each row group includes metadata for every column:
- Min / Max values
- Null count
- Encoding type
- File offset
This metadata lets engines skip reading whole row groups if they don’t match your filter.
Example:
If a row group’s metadata says:
"amount": {
"min": 0,
"max": 999
}
and your query is:
SELECT * FROM data WHERE amount > 1000
→ The engine skips that row group entirely, without reading the data.
🧠 Summary: When to Use Parquet
| Use Case | Parquet Suitable? |
|---|---|
| Big datasets (GBs/TBs) | ✅ Yes |
| Selective column queries | ✅ Yes |
| Fast filters with ranges | ✅ Yes |
| Real-time web apps | ❌ No |
| Frequent updates/deletes | ❌ No |
| Configs / data sharing | ❌ Use JSON/CSV |
Is Parquet File Human readable?
No, Parquet is not human-readable. It is a binary file format, which means you cannot open it in a text editor and make sense of the contents like you can with JSON, CSV, or plain text files. The data is encoded, compressed, and stored in a columnar layout optimized for machines and analytical engines — not humans.
However, you can read and inspect Parquet files using tools like:
VSCode extensions or data viewers
parquet-tools (CLI)
Python (with pandas, pyarrow, or fastparquet)
DuckDB or Spark SQL (SELECT * FROM 'file.parquet')
🔚 Final Thoughts
Parquet is not a replacement for SQL databases or JSON — it’s a specialized tool for big, structured data where speed and scalability matter.
- Use JSON for human-readable configs and data interchange
- Use SQL databases for real-time, transactional systems
- Use Parquet when you’re processing large datasets and need fast analytics